캐시
캐시란 데이터를 미리 복사해 놓는 임시 저장소이자
빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리를 말한다.
이를 통해 데이터 접근 시간의 단축, 데이터를 다시 계산하는 시간 등을 절약할 수 있다.
캐시의 예는 CPU 레지스터가 대표적이다.
CPU가 메모리로부터 데이터를 가져올 때의 시간이 길어,
그 중간에 레지스터 계층을 둬 속도차이를 해결하는 것이다.
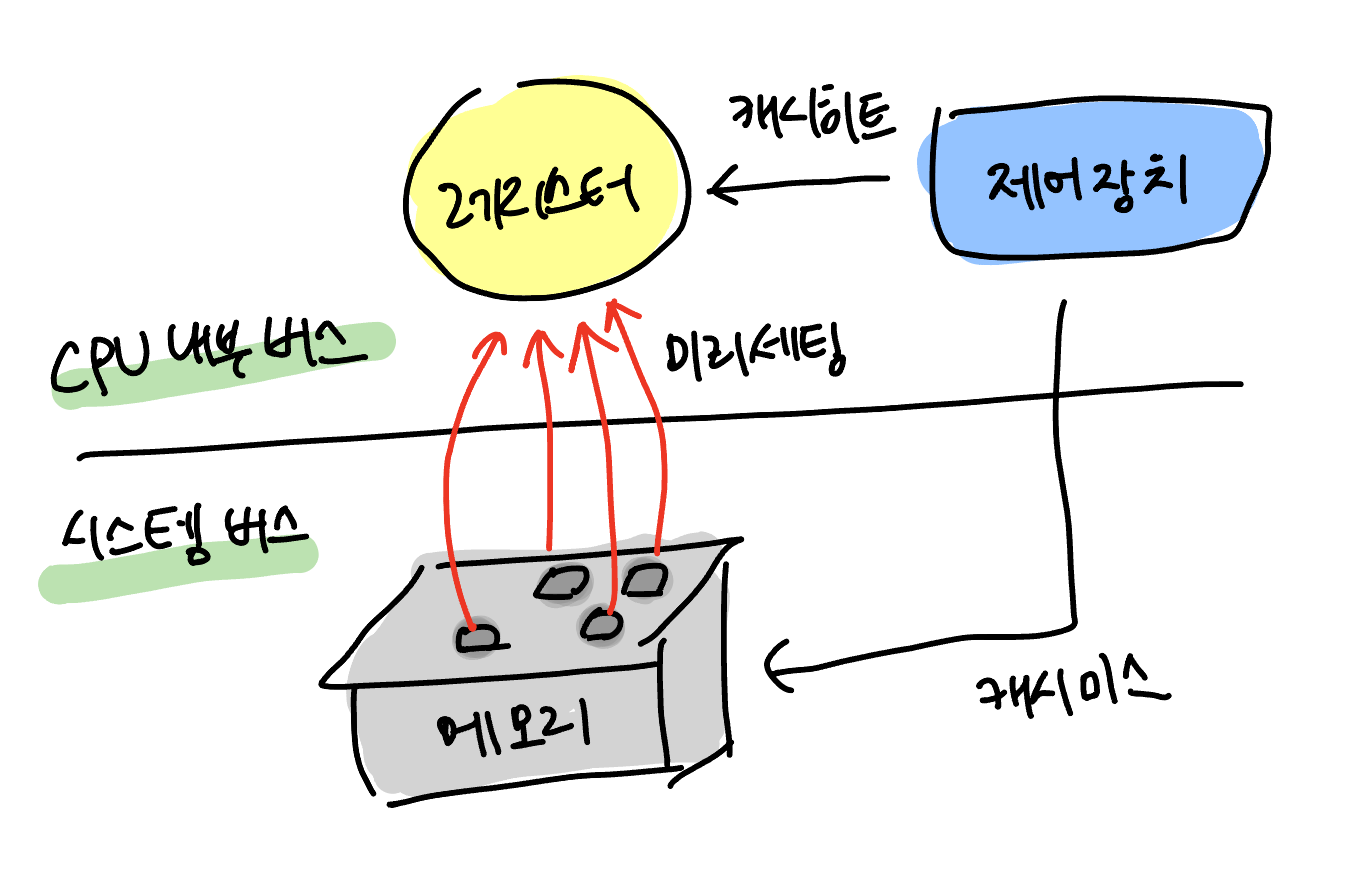
캐시 히트란 캐시에서 원하는 데이터를 찾은 것을 말하며,
캐시 미스란 캐시에서 원하는 데이터를 찾지 못한 것을 말한다.
위 그림과 같은 경우, 캐시미스가 일어나면
메모리로 가 원하는 데이터를 레지스터에 등록하게 된다.
캐시는 우리가 사용하는 서비스 내부에서도 많이 찾아볼 수 있다.
예를 들어, 데이터베이스에서 redis 데이터베이스를 캐시 계층으로 둔 사례가 있으며,
웹서버 앞단에 nginx 서버를 캐시계층으로 둔 사례가 있다.
캐시 지역성의 원리
캐시를 설정할 때는 자주 사용하는 데이터를 기반으로 설정해야 한다.
이 때 지역성을 기반으로 설정되는데,
지역성은 시간 지역성(temporal locality)과 공간 지역성(spatial locality)로 나뉘게 된다.
시간 지역성
시간 지역성은 최근 사용한 데이터에 다시 접근하려는 특성을 말한다.
공간 지역성
공간 지역성은 최근 접근한 데이터를 이루고 있는 공간이나,
그 가까운 공간에 접근하는 특성을 말한다.
지역성의 원리에 대한 자바스크립트 예시 코드는 아래와 같다.
let arr = Array.from({length: 10}, () => 0);
console.log(arr);
for(let i = 0; i < 10; i += 1) {
arr[i] = i;
}
console.log(arr);
/*
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ]
[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ]
*/최근 사용한 변수 i에 대해 계속해서 +=1 을 반복한다는 점에서 시간 지역성과,
최근 사용했던 공간인 arr 라는 배열에 i가 할당되며 연속적으로 접근하는 공간 지역성을 볼 수 있다.
npm node-cache를 install 하여 간단한 캐시를 실습해볼 수 있다.
const express = require('express');
const NodeCache = require('node-cache');
const app = express();
const cache = new NodeCache();
const obj = {
"userId": 1,
"id": 1,
"title": "is World hello?",
"completed": false
}
app.get('/walwal', (req, res) => {
const value = cache.get('walwal');
if(value) {
console.log("캐시가 있다. 캐시를 전달한다.");
return res.send(value);
} else {
//가상의 데이터베이스 로직
console.log("캐시가 없다. 캐시를 세팅하고 데이터베이스로부터 값을 가져온다.");
setTimeout(()=>{
cache.set('walwal', obj);
return res.json(obj);
}, 2000);
}
});
app.listen(3000, () => {
console.log("Cache server is runing on port 3000 :: http://127.0.0.1:3000/walwal");
});
캐시 매핑
캐시의 크기는 메모리보다 항상 작기 때문에
효율적으로 매핑하는 것이 중요하다.
매핑 방식에는 직접 매핑, 연관 매핑, 집합-연관 매핑이 있다.
직접 사상, 연관 사상, 집합-연관 사상이라고도 부른다.
직접 매핑
직접 매핑(direct mapping)이란 메모리의 특정 블록은 특정 캐시 라인에만 매핑할 수 잇는 방식이다.
예를 들어, 메모리가 A개의 페이지, 캐시가 B개의 페이지로 구성된다고 할 때,
메모리의 페이지 수 A를 B개로 나누는 것이다. A/B
이렇게 되면 메모리의 페이지 수는 B * 블록의 수가 된다.
메모리가 1~100이 있고, 캐시가 1~5가 있다면,
캐시 : 메모리는 1 : 1~20, 2 : 21~40 ... 방식으로 매핑된다.

내부적으로 운영체제는 똑같은 크기의 페이지(보통 4kb)로 나눠서 관리 하며,
<P, D> 로 나누어 관리한다.
P(Page Number)는 페이지 번호,
D(Page Offset)는 페이지 번호로부터 해당 주소까지의 거리를 의미한다.
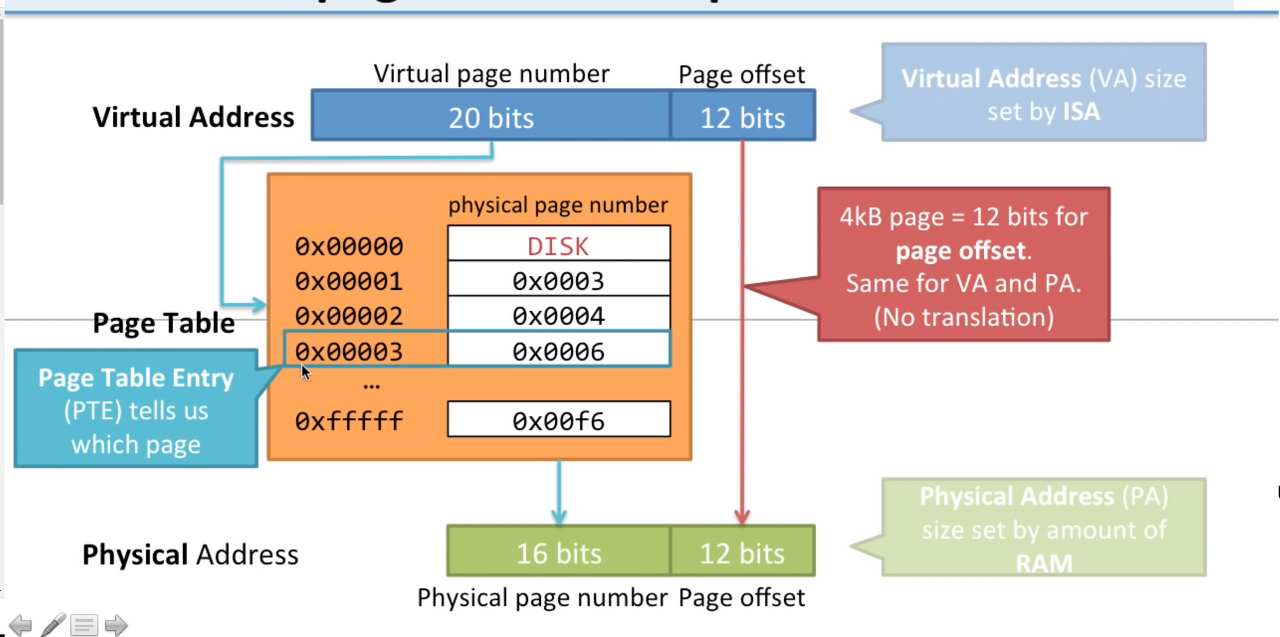
위 그림처럼 가상주소는 20bits로 주소를 관리하여 더 많은 주소를 할당할 수 있으며,
이러한 주소가 16bits의 실제주소로 페이지 테이블을 통해 변환된다.
D(page offset)은 변환되지 않고, P(page number)가 변환되는 것이다.
즉, 매핑되는 부분은 P이기 때문에 P만 보면 된다.
P를 직접 매핑에서는 {tag, bd}로 세분화하여 구현한다.
bd(block distance)와 블럭을 위한 태그를 기반으로 <tag, bd, D>로 세분화하여
bd가 같은 라인만 매핑이 된다.
직접 매핑은 블록만 확인하면 되기 때문에,
처리가 빠르다는 장점이 있다.
대신 스와핑이 빈번하게 발생할 수 있다.
같은 bd가 같은 라인만 매핑이 가능하기 때문에 다른 자리가 비어있더라도
사용할 수 없고, 그로 인해 스와핑이 잦아지는 것이다.
연관 매핑
연관 매핑(associative mapping)이란 순서를 일치시키지 않고
관련 있는 캐시와 메모리를 매핑하여
메모리의 콘텐츠가 캐시의 어느 위치에도 올라갈 수 있는 방법을 말한다.
스와핑이 덜 일어나는 대신,
캐시의 모든 블록을 탐색해야 해 속도가 직접 매핑보다 느리다.
연관 매핑은 bd가 필요하지 않아, bd와 tag를 합한 P로 설명한다.
집합 연관 매핑
집합 연관 매핑(set associate mapping)은 집합을 나누고 (정해진 집합을 만드는 면서에서 직접 매핑적)
해당 집합에는 bd만 같으면 들어올 수 있게 하는데,
이 때 어떤 블록에도 들어올 수 있게 하는 것이다.
이를 통해 모든 블럭을 찾을 필요 없이,
특정 블록을 찾게 하여 탐색 비용을 낮춤으로써 직접 매핑의 장점과
스와핑을 완화시키는 연관 매핑의 장점을 모두 지닌다.
예를 들어, 캐시에서 bd가 0인 집합을 2개로 나누고
bd가 같은 것만 들어올 수 있게 하는 것이다.
bd가 많지만 bd를 0 또는 1 밖에 없게 하고, 집합을 2개로 나눈다.
bd가 0인 경우 2개, 1인 경우 2개가 들어갈 수 있게 나누는 것을 말한다.
'컴퓨터 공학 & 통신' 카테고리의 다른 글
| [키워드 정리/운영체제] 펌웨어 VS 운영체제 (0) | 2023.07.27 |
|---|---|
| [개념 정리/운영체제] 메모리 할당 (1) | 2023.07.27 |
| [개념 정리/운영체제] CPU 스케줄링 알고리즘 (2) | 2023.07.27 |
| [개념 정리/운영체제] 교착 상태(deadlock) (0) | 2023.07.26 |
| [개념 정리/운영체제] 경쟁 상태 해결 방법 - 뮤텍스, 세마포어, 모니터 (0) | 2023.07.26 |